Data Lake vs Data Warehouse
Difference between Data Lake and Data Warehouse
| 特徵 | 資料湖 (Data Lake) | 資料倉庫 (Data Warehouse) |
|---|---|---|
| 數據類型 | 支援結構化和非結構化數據,原始數據格式。 | 主要支援結構化數據,通常經過預處理和轉換。 |
| 數據存儲 | 中央存儲庫,原始格式保存數據。 | 數據被加工、壓縮,以最佳方式存儲。 |
| 數據架構 | 靈活,不需要預先定義結構。 | 預先定義結構,支援星型或雪花型數據模型。 |
| 查詢和分析 | 即席查詢和分析,支援多種工具。 | 非即席查詢,主要支援商業智能工具。 |
| 成本 | 相對較低,因為原始數據保存,無需預處理。 | 相對較高,因為需要預處理和儲存優化。 |
| 用途 | 適用於彈性的數據存儲和分析,支援多種數據類型。 | 適用於結構化數據的報表、分析和企業決策。 |
| 時間性能 | 適用於較長時間跨度的分析和處理。 | 適用於即時或近實時的數據分析。 |
Data Lake
Delta Lake
Delta Lake 是一個開源的數據湖(Data Lake)儲存層,它在 Apache Spark 上構建,提供了 ACID(原子性、一致性、隔離性、持久性)事務的能力,透過在 Data Lake 加了一些 Data Warehouse 級別的特性,帶來數據可靠性和快速分析能力,實現 Lakehouse
- 事務支持: Delta Lake 提供了事務的支持,這意味著它能夠保證數據的一致性和可靠性。這使得在數據湖中進行複雜的數據操作時更加安全。
- 原子性操作: Delta Lake 支持原子性的更新、插入和刪除操作,這意味著數據湖的操作可以更加可控,減少了數據錯誤的風險。
- Schema 驗證: Delta Lake 可以進行模式(Schema)的驗證,確保數據的結構是正確的。這有助於保持數據的一致性和質量。
- 增量讀寫: Delta Lake 支持增量的寫入和讀取操作,這使得在大數據環境中進行高效的數據湖操作成為可能。
- 版本控制: Delta Lake 自帶版本控制,可以追蹤數據的歷史變更,並且支持回滾到先前的版本。
Delta Table vs External Table
| 特點 | Delta Table | External Table |
|---|---|---|
| 存儲位置 | Delta Table 的數據存儲在 Delta Lake 中,通常在分布式文件系統上。 | External Table 的數據存儲在外部位置,例如分布式文件系統(HDFS)或對象存儲(如 Amazon S3)。 |
| 事務支持 | 支持 ACID 事務,提供原子性、一致性、隔離性和持久性。 | 不提供事務支持,主要用於輕量查詢和操作外部數據。 |
| 版本控制 | 具有內建的版本控制功能,可以追蹤數據的歷史變更。 | 不提供內建的版本控制,需要額外實現或使用外部工具來管理歷史數據。 |
| 增量讀寫 | 支持增量的數據寫入和讀取,可以有效處理大數據湖的數據操作。 | 主要用於輕量操作,對外部數據源的寫入通常需要整個文件的替換而非增量。 |
| 模式驗證 | 提供模式(Schema)驗證,確保數據的結構是正確的。 | 通常不提供模式驗證,數據結構由外部數據源的定義確定。 |
| 適用情境 | 適用於需要事務支持、版本控制、增量操作以及結構化數據處理的場景。 | 適用於輕量查詢,無需事務支持,且數據已經存儲在外部位置的場景。 |
Multi-Hop Architecture
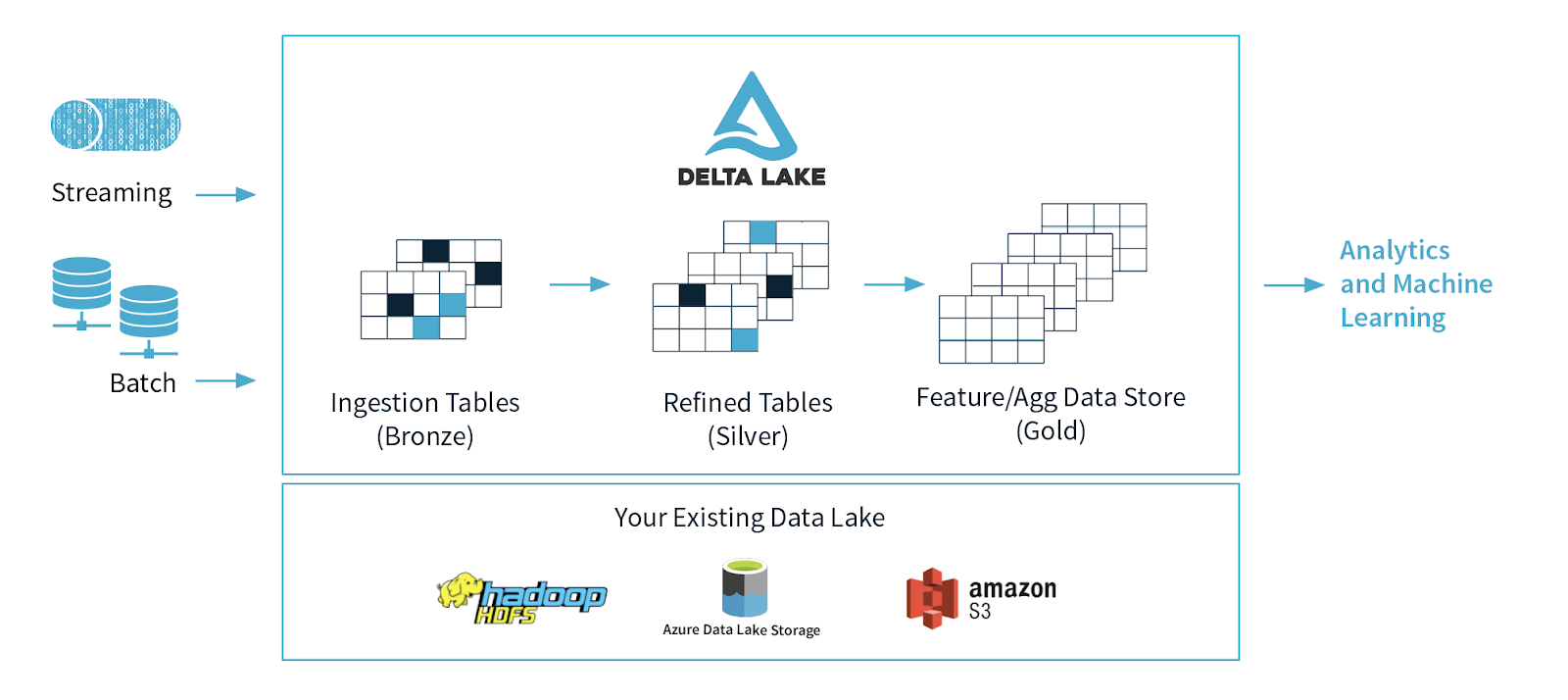
- Bronze Table: 這是數據管道中的原始數據層。Bronze table 包含從源頭提取的原始數據,可能是未經處理或僅經過輕微處理的數據。這個層次的表通常包含原始格式的數據,並可能還包含一些基本的數據清理。
- Silver Table: Silver table 是在原始數據的基礎上進行進一步處理和清理後的表。在這個階段,數據可能已經被結構化,缺失值已經處理,可能還進行了一些初步的轉換。Silver table 的目的是提供比原始數據更整潔、更易於理解的格式。
- Golden Table: Golden table 是經過最終加工和準備的數據,通常用於支持業務報告、分析和決策。這一層次的表包含高度結構化的數據,可能包括計算字段、業務指標以及已經經過多方面驗證和確認的數據。Golden table 是供最終用戶和報告系統使用的主要數據源。
Data Warehouse
OLAP (Online Analytical Processing)
OLAP 代表線上分析處理(Online Analytical Processing),針對大量讀取、低寫入工作負載進行優化,是一種用於對大量數據進行快速、互動性分析的計算機處理方法。主要用於商業智能(BI)和數據分析領域,讓用戶能夠以多維度的方式探索和分析數據。
Fact Table vs Dimension Table
| 特點 | 事實表(Fact Table) | 維度表(Dimension Table) |
|---|---|---|
| 定義 | 包含數據的事實或實際數值,如銷售金額、數量。 | 包含描述事實的上下文和分類信息的屬性,如時間、產品。 |
| 結構 | 扁平結構,大量的 column 和相對較少的 row | 層次化結構,相對較少的 column 和更多的 row |
| 關聯 | 與多個維度表相關聯,提供上下文信息。 | 與事實表之間的關聯,基於主鍵-外鍵的關聯。 |
| 示例 | 包含銷售金額、數量、成本等度量。 | 包含產品、時間、地區等維度的描述信息。 |
| 目的 | 衡量業務績效,提供量化的數據。 | 將數據放入上下文,提供分析的屬性描述。 |
| 類型 | 數值型數據,可度量、可數量。 | 文本型描述性信息,用於分類和上下文。 |
Star Schema 分析範例
Sales_Fact 包含實際銷售數據,如銷售金額和銷售數量
| Order_ID | Product_ID | Date_ID | Sales_Amount | Sales_Quantity |
|---|---|---|---|---|
| 1 | 101 | 20230101 | 5000 | 10 |
| 2 | 102 | 20230102 | 7500 | 15 |
| 3 | 103 | 20230103 | 3000 | 6 |
Product_Dimension 產品相關資訊
| Product_ID | Product_Name | Category_ID | Brand_ID |
|---|---|---|---|
| 101 | Laptop A | 1 | 201 |
| 102 | Smartphone B | 2 | 202 |
| 103 | Tablet C | 1 | 203 |
Date_Dimension 銷售日期相關資訊
| Date_ID | Date | Year | Month | Day |
|---|---|---|---|---|
| 20230101 | January 1, 2023 | 2023 | 01 | 01 |
| 20230102 | January 2, 2023 | 2023 | 01 | 02 |
| 20230103 | January 3, 2023 | 2023 | 01 | 03 |
透過 SQL 執行這個查詢將得到每個產品類別在 2023 年 1 月的銷售總額
SELECT
d.Year AS Year,
d.Month AS Month,
p.Product_Name AS Product_Name,
p.Category_ID AS Product_Category,
SUM(f.Sales_Amount) AS Total_Sales
FROM
Sales_Fact f
JOIN
Date_Dimension d ON f.Date_ID = d.Date_ID
JOIN
Product_Dimension p ON f.Product_ID = p.Product_ID
WHERE
d.Year = 2023 AND d.Month = '01'
GROUP BY
d.Year, d.Month, p.Product_Name, p.Category_ID;
結果:
| Year | Month | Product_Name | Product_Category | Total_Sales |
|---|---|---|---|---|
| 2023 | 01 | Laptop A | 1 | 5000 |
| 2023 | 01 | Smartphone B | 2 | 7500 |
| 2023 | 01 | Tablet C | 1 | 3000 |